Skip to content
How To
Tech
Action
Adventure
Review
Contact us
Review
Tozo HT2: Affordable Noise-Cancelling Headphones Review
ANIME MOVIES
Epic Seven Tier List – Best Characters Or Heroes
ANIME SERIES
Cowboy Bebop (Season 1 + Movie) 1080p Dual Audio HEVC
Latest Post
Review
Tozo HT2: Affordable Noise-Cancelling Headphones Review
ANIME MOVIES
Epic Seven Tier List – Best Characters Or Heroes
ANIME SERIES
Cowboy Bebop (Season 1 + Movie) 1080p Dual Audio HEVC
Anime
Vinland Saga (Season 01) 1080p Dual Audio [Multi-Subs] HEVC
General
Beyond the Box: Exploring Every Aspect of Tozo Tonal Fits T21
Tech
Raysync’s Strategies for High-Performance Bulk File Transfer
Technology
Tech
Raysync’s Strategies for High-Performance Bulk File Transfer
Tech
Rytr vs Autoblogging.ai
Tech
Comparison of File Transfer Efficiency and Enhancement Solution
Tech
ILML2: The Ultimate TV Experience
Tech
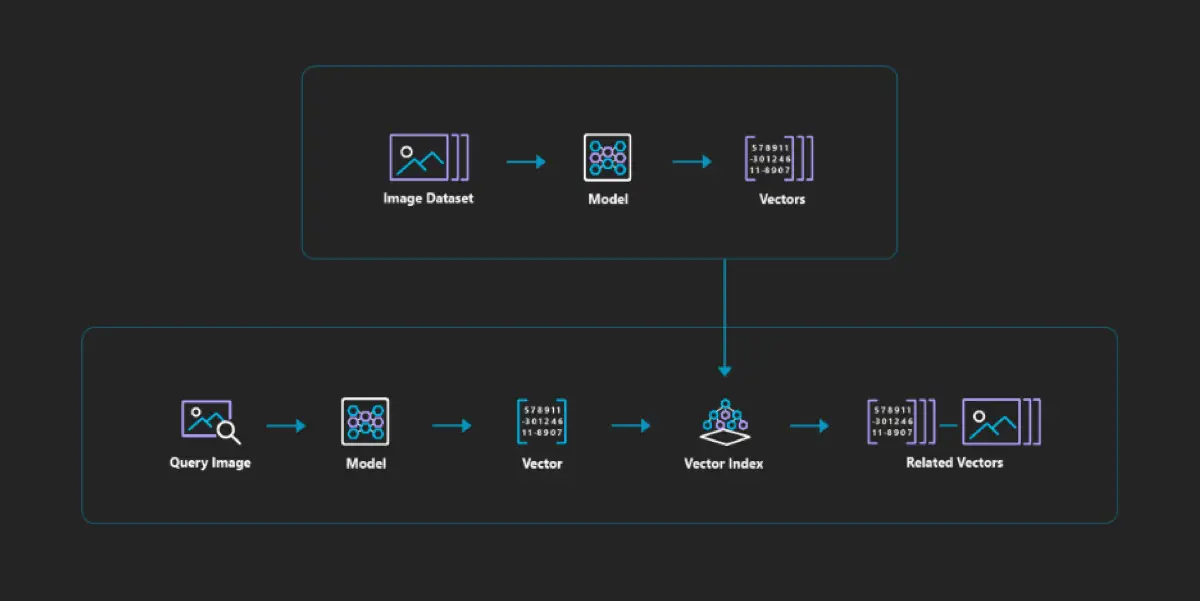
Vector Search Algorithms: Unraveling the Core Principles
Tech
Overwatch System Requirements – Can I run it on my PC?
Action
Action
ANIME SERIES
Pluto (Season 1) 1080p Dual Audio HEVC
Action
ANIME SERIES
Drama
Fantasy
Shakugan no Shana (Season 1-3 + Movie + OVA) 720p Dual Audio HEVC
Action
Adventure
ANIME MOVIES
ANIME SERIES
Fantasy
romance
Sword Art Online (All Seasons + Movie + Gun Gale Online + OVAs) 1080p Dual Audio HEVC
Fantasy
Action
ANIME SERIES
Drama
Fantasy
Shakugan no Shana (Season 1-3 + Movie + OVA) 720p Dual Audio HEVC
Action
Adventure
ANIME MOVIES
ANIME SERIES
Fantasy
romance
Sword Art Online (All Seasons + Movie + Gun Gale Online + OVAs) 1080p Dual Audio HEVC
ANIME SERIES
Comedy
Ecchi
Fantasy
Peter Grill and the Philosopher’s Time (Season 1) 1080p [UNCENSORED] Dual Audio HEVC
Action
ANIME SERIES
Comedy
Ecchi
Fantasy
romance
School
Shounen
Trinity Seven (Season 1 + OVAs + Movie) 1080p Dual Audio [Multi Subs] HEVC
ANIME SERIES
Fantasy
My Happy Marriage (Watashi no Shiawase na Kekkon) (Season 1) 1080p Dual Audio HEVC
ANIME MOVIES
ANIME SERIES
Fantasy
Slice of Life
Supernatural
Beyond the Boundary (Season 1 + Movies + Special) 1080p Dual Audio HEVC
Comedy
ANIME SERIES
Comedy
Drama
Bakuman (Season 1-3 + OVAs) 1080p Eng Sub HEVC
ANIME SERIES
Comedy
School
Haven’t You Heard? I’m Sakamoto (Sakamoto Desu ga?) (Season 1 + OVAs) 1080p Dual Audio HEVC
ANIME SERIES
Comedy
Ecchi
Fantasy
Peter Grill and the Philosopher’s Time (Season 1) 1080p [UNCENSORED] Dual Audio HEVC
No Post Found
Shounen
Action
ANIME SERIES
Comedy
Ecchi
Fantasy
romance
School
Shounen
Trinity Seven (Season 1 + OVAs + Movie) 1080p Dual Audio [Multi Subs] HEVC
ANIME SERIES
Comedy
romance
School
Shounen
Rosario to Vampire (Rosario + Vampire) (Season 1-2) 1080p Dual Audio HEVC
ANIME MOVIES
ANIME SERIES
Comedy
Drama
School
Shounen
Sports
Haikyuu!! (Season 1-4 + OVAs + Movie) 1080p Dual Audio HEVC [Eng Subs]
Adventure
Action
Adventure
ANIME MOVIES
ANIME SERIES
Fantasy
romance
Sword Art Online (All Seasons + Movie + Gun Gale Online + OVAs) 1080p Dual Audio HEVC
Action
Adventure
ANIME SERIES
Boruto: Naruto Next Generations 1080p Dual Audio HEVC
Action
Adventure
ANIME SERIES
Drama
Fantasy
Mystery
Tower of God (Season 1) 1080p Dual Audio [Multi-Subs] HEVC
Action
Adventure
ANIME SERIES
Fantasy
Harem
School
The Familiar of Zero (Seasons 1-4) + OVAs 1080p Dual Audio [Eng Subs]
Action
Adventure
ANIME SERIES
Drama
Sci-Fi
86 – Eighty Six (Season 1 + Special) 1080p Dual Audio HEVC | Episode 10
Action
Adventure
ANIME MOVIES
ANIME SERIES
Comedy
Shounen
Super Power
Naruto Shippuden (Season 1-21 + Naruto + Movies + OVAs) 1080p Dual Audio HEVC
romance
ANIME SERIES
romance
My Love Story with Yamada-kun at Lv999 (Season 1) 1080p Dual Audio HEVC
Action
Adventure
ANIME MOVIES
ANIME SERIES
Fantasy
romance
Sword Art Online (All Seasons + Movie + Gun Gale Online + OVAs) 1080p Dual Audio HEVC
Action
ANIME SERIES
Comedy
Ecchi
Fantasy
romance
School
Shounen
Trinity Seven (Season 1 + OVAs + Movie) 1080p Dual Audio [Multi Subs] HEVC
You Missed
Review
Tozo HT2: Affordable Noise-Cancelling Headphones Review
ANIME MOVIES
Epic Seven Tier List – Best Characters Or Heroes
ANIME SERIES
Cowboy Bebop (Season 1 + Movie) 1080p Dual Audio HEVC
Anime
Vinland Saga (Season 01) 1080p Dual Audio [Multi-Subs] HEVC
Search for:

















![Trinity Seven (Season 1 + OVAs + Movie) 1080p Dual Audio [Multi Subs] HEVC](https://techsdroid.com/wp-content/uploads/2021/09/Trinity-Seven-Season-1-OVAs-Movie-1080p-Dual-Audio-Multi-Subs-HEVC.png)







![Tower of God (Season 1) 1080p Dual Audio [Multi-Subs] HEVC](https://techsdroid.com/wp-content/uploads/2021/09/Tower-of-God-Season-1-1080p-Dual-Audio-Multi-Subs-HEVC.png)